
AWS Instance Backup Automation with Nectus
Having your data backed up and secured is crucial for business-critical systems. If your servers run in AWS infrastructure,
then you already have an advantage of performing backup of the hosted instances using Amazon built-in features.
This can be performed manually using AWS console the following way. First, select Instances menu from EC2 Dashboard.
Then select an instance you would like to backup.
In Description tab you will see the Block devices attached to the selected instance.
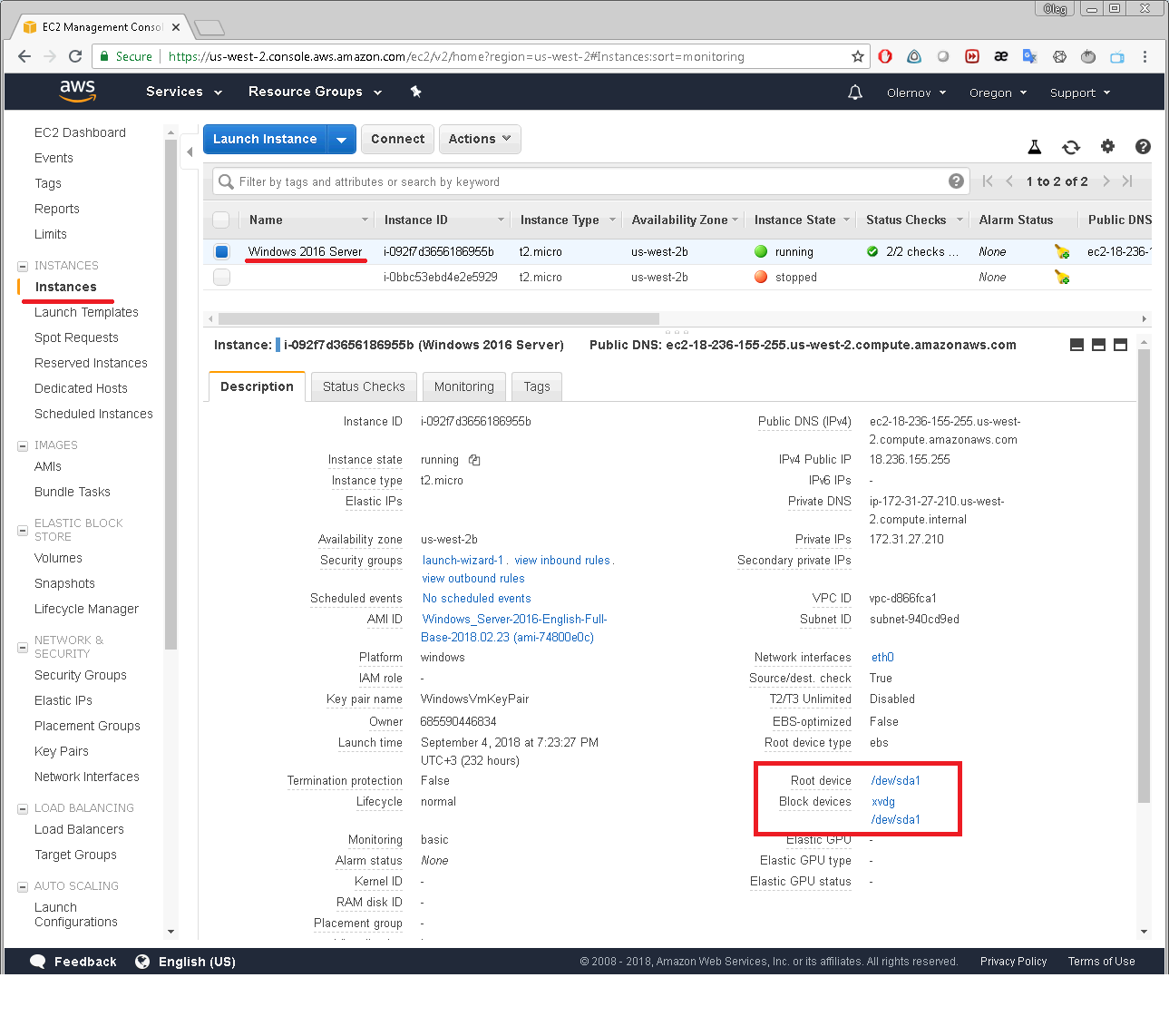
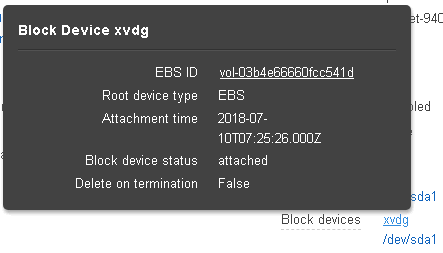
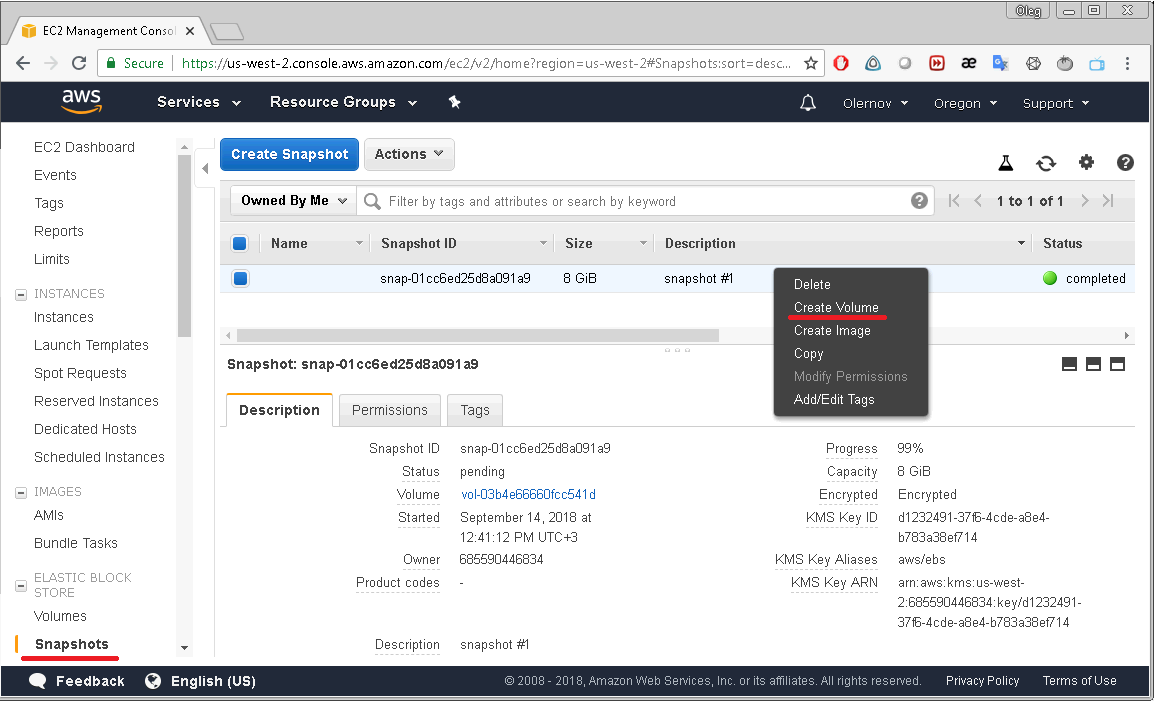
Clicking on one of the block devices will bring up the window displaying the block device’s EBS ID:
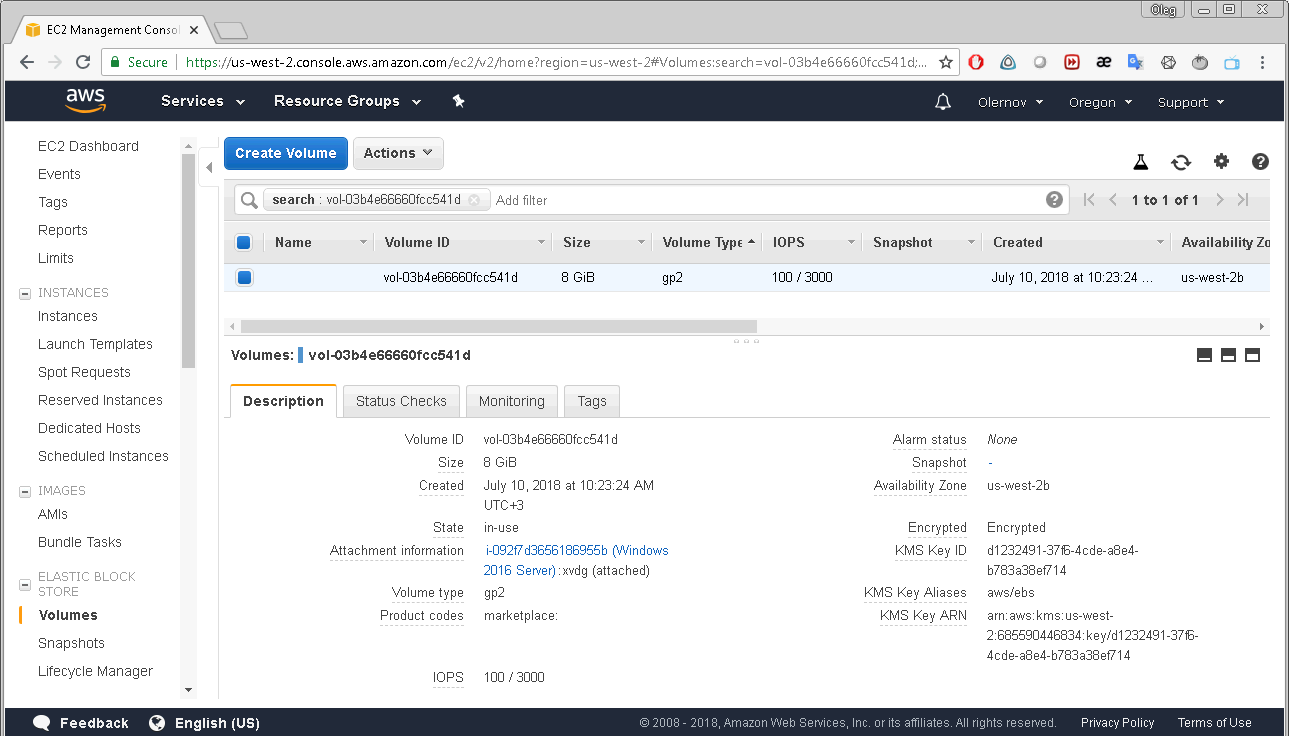
By clicking that EBS ID you get to the Volumes menu of the EC2 Dashboard:
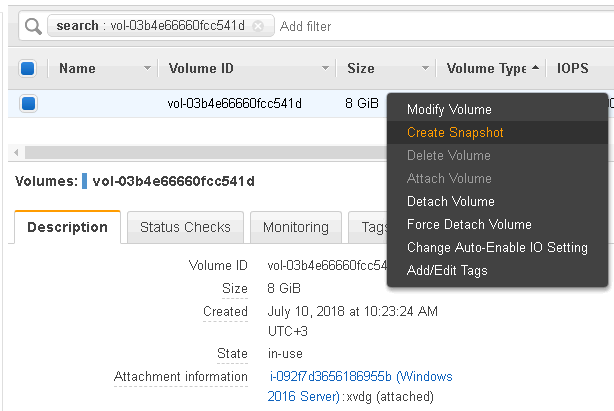
Right-click on the selected volume will display a menu with “Create snapshot” option.
After selecting this option you have to enter a description of your snapshot and the snapshot will be created.
After that the snapshot created will appear on the list displayed on the EC2 Dashboard/Snapshots page. To restore data from that snapshot you should select
“Create Volume” option from the snapshot’s context-menu. A new volume will appear with exactly the same data you had on your volume when snapshot was created.
But taking snapshots manually is hardly an option, especially if you deal with a lot of the EC2 instances. This process must be automated.
One of possible solutions is utilizing the Nectus AWS backup functionality. Nectus is able to take snapshots of your volumes constantly and
regularly with the required periodicity according to the backup profiles you set.
The following steps will show how to enable and set up the automated backup of AWS instances using Nectus. First you need to set up your backup profiles.
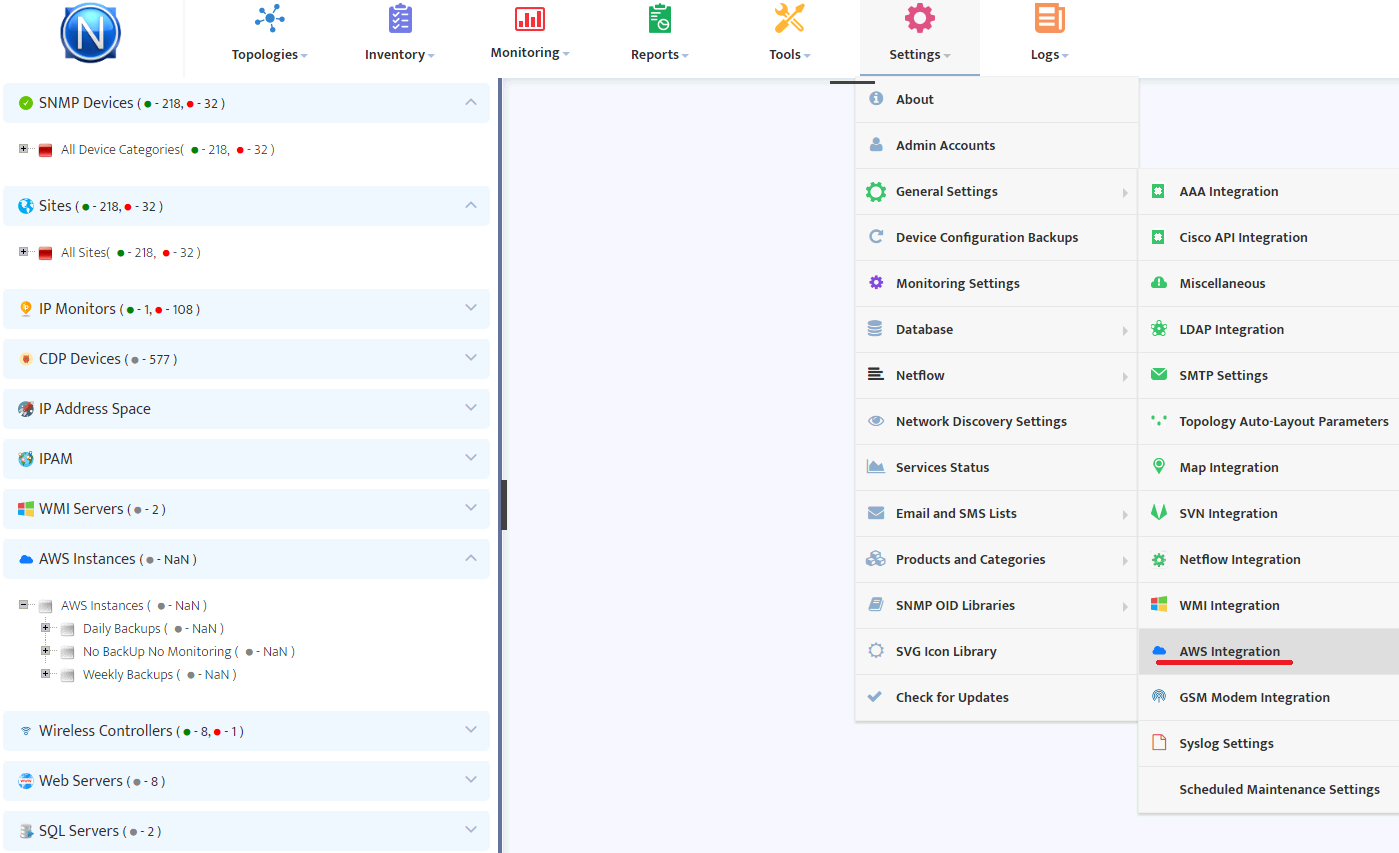
Select Settings/General Settings/AWS Integration menu.
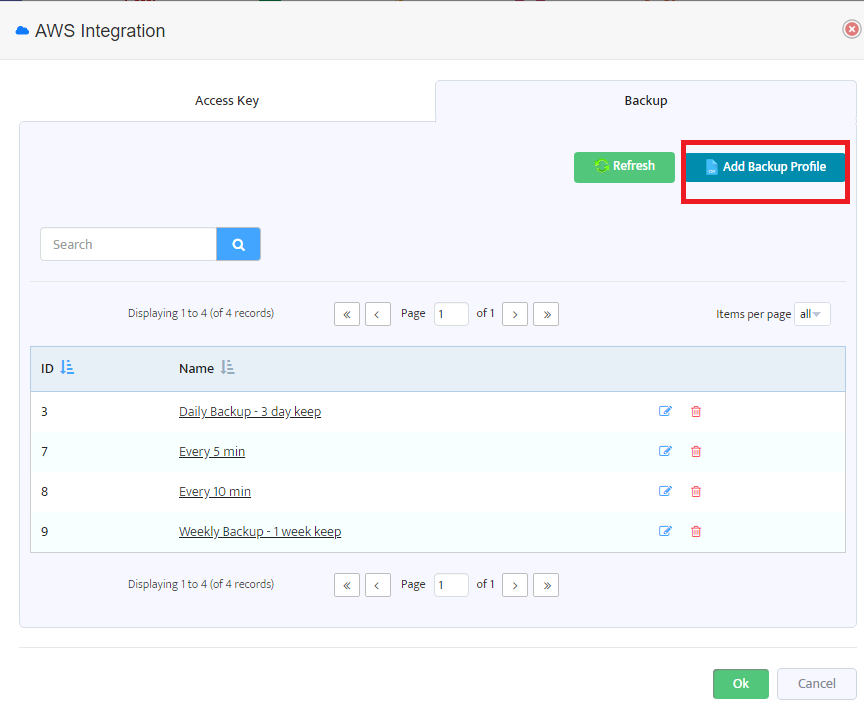
In the “Backup” tab you will see backup profiles already created and also the “Add Backup Profile” button.
Pressing this button will open the following “Add New AWS Backup Profile” dialog.
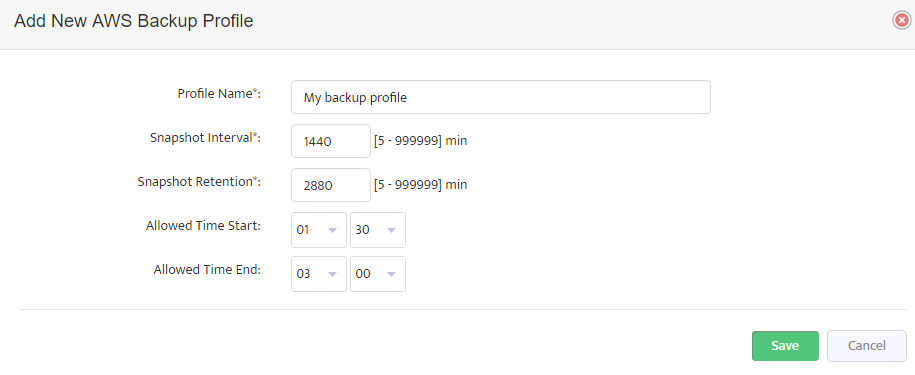
Here you can enter a name for a new backup profile, periodicity of snapshots creation (Snapshot Interval), period of retention for snapshots created (Snapshot retention)
and the allowed time interval to take snapshots (this setting is available only if Snapshot Interval is 1440 minutes or more).
Pressing “Save” button will add the new backup profile to the list. Editing of existing profiles is also possible.
You can create any number of backup profiles for different purposes.
For example, you may want to backup your most critical production instances quite often (every 5 minutes) but your test servers rarely (once a day or maybe even once a week).
The procedure of taking a snapshot is free of charge from Amazon but storing them is charged depending on the volume (see AWS EC2 pricing).
That should be considered when choosing the Snapshot retention period.
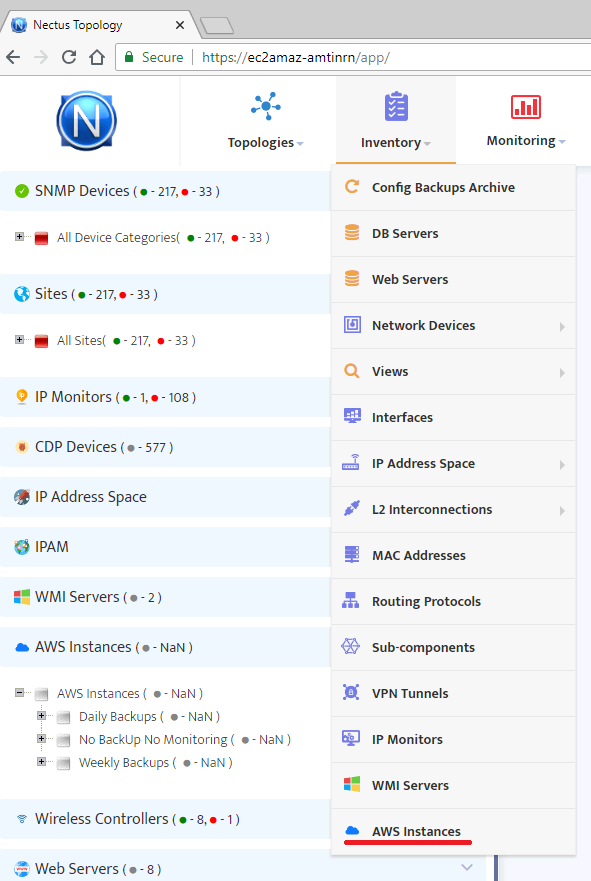
After you have set the required backup profiles, it is time to assign them to your instances. To perform it select “AWS Instances” from the “Inventory” menu.
In the form displayed you can see a list of already existing instance groups. To create a new AWS instance group press the button “Create new Group” at the top-right of the form.
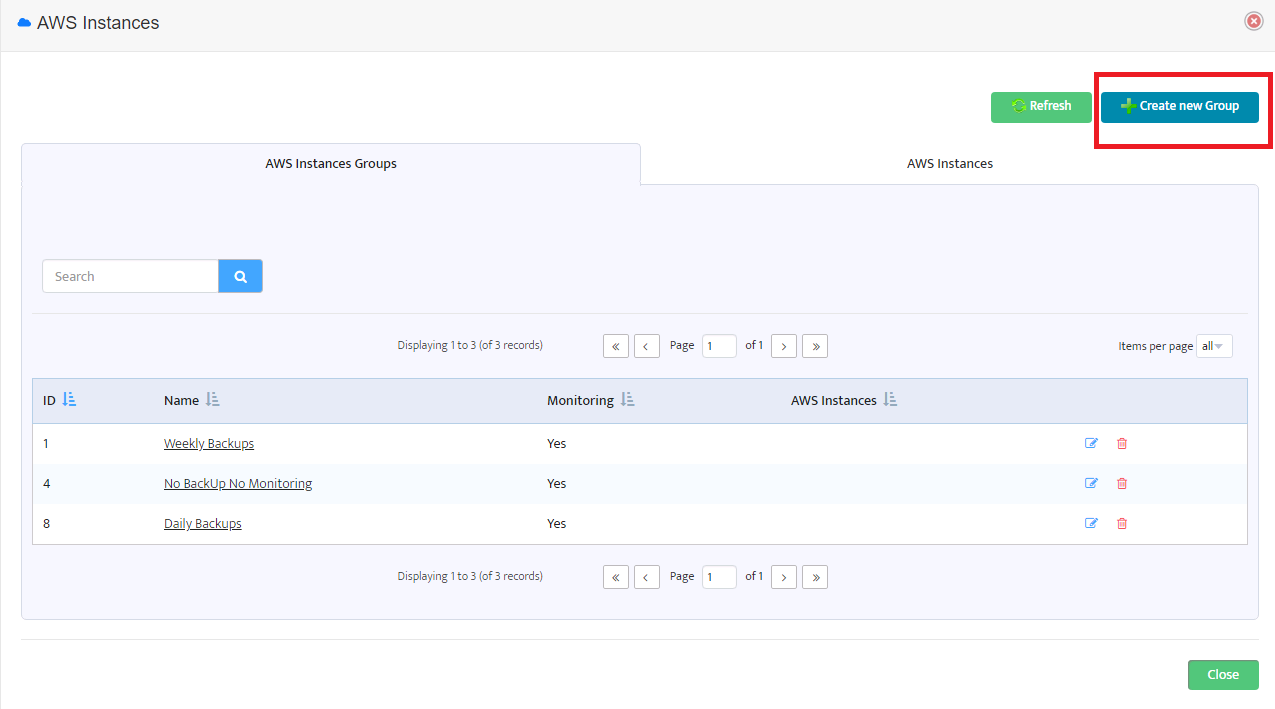
In the window opened you should set a new group name, check the “Enable Backup” box and choose one of the backup profiles created earlier.
If the box is not checked, then no backups will be performed for instances of this group.
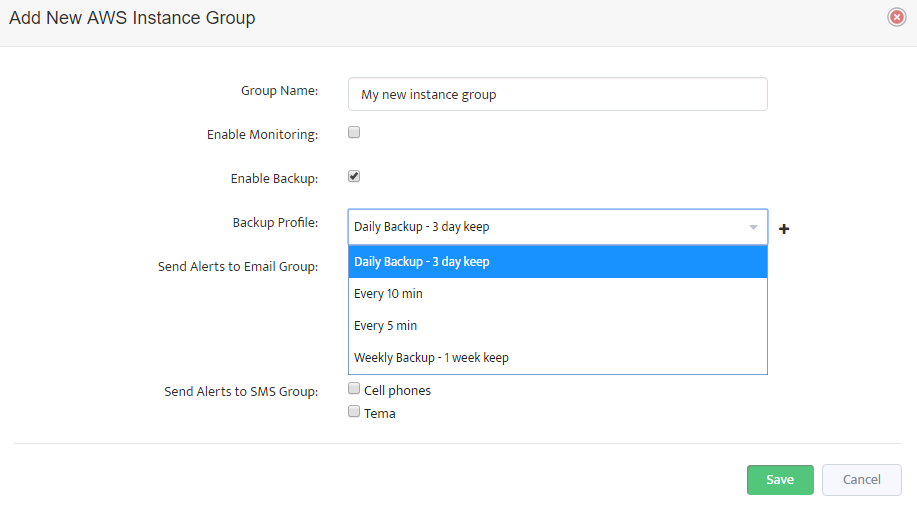
Now when you have backup profiles assigned to AWS instance groups you can switch to the next tab “AWS Instances”.
The next window displays a list of AWS instances.
Each instance belongs to one of the AWS instance groups and so the group settings affect the instance backup policy.
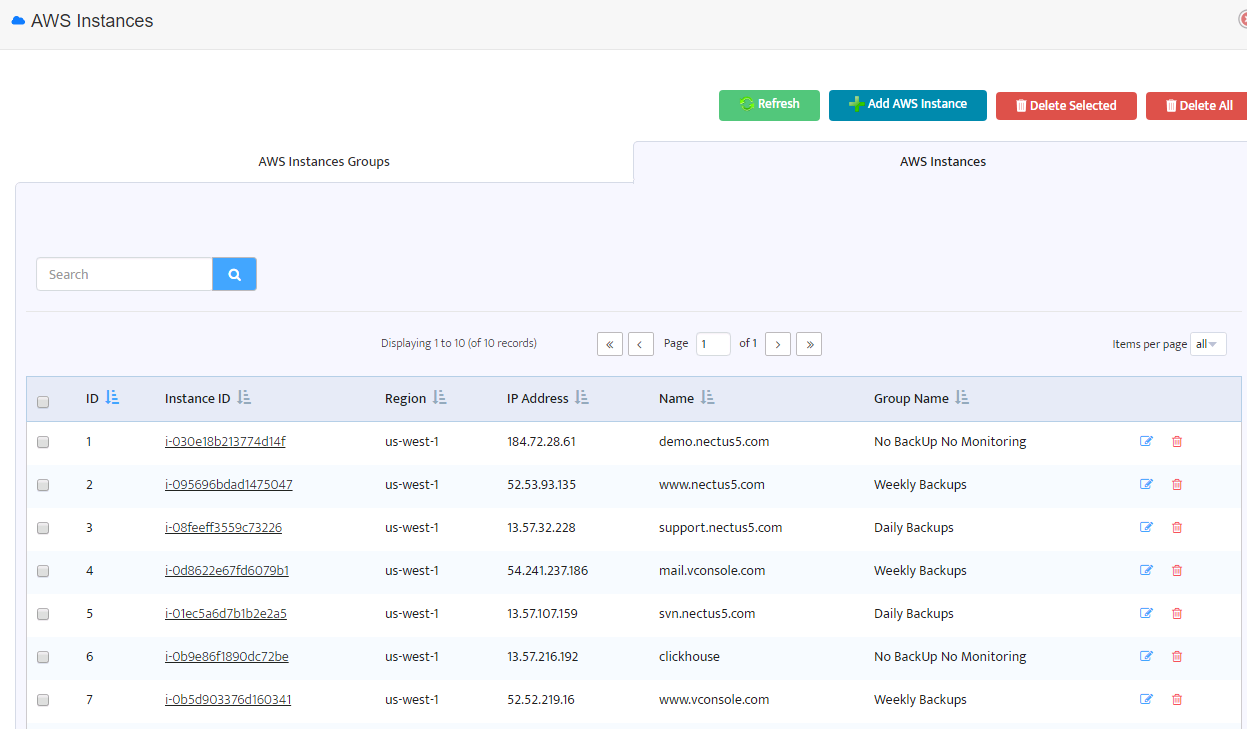
To change backup profile for an instance you should move it to another instance group with appropriate backup profile.
For example, if you want to change backup profile for “www.nectus5.com” from “Weekly Backups” to “Daily Backups”
just click on the Instance ID and change AWS instance group.
After such setup Nectus will automatically start creating new snapshots and deleting old ones.
You will see those snapshots in your EC2 Dashboard.
Enabling Monitoring for SNMP Interfaces
Network Monitoring, Technical NotesEnabling Monitoring for SNMP Interfaces
In this chapter, you’ll learn how to enable monitoring and create monitoring groups for SNMP Interfaces.
The specific topics we will cover in this chapter are:
1. Automatic Discovery and Grouping of SNMP Interfaces
During the Discovery phase all network Interfaces are automatically added to the group called “No Monitoring Group.” This group has all monitoring functionality disabled and serves as a parking space for all unmonitored Interfaces.
To enable monitoring for a particular Interface you must move that interface from the “No Monitoring Group” to any group that has the monitoring checkbox set to “ON” and has a Monitoring Profile assigned.
2. Creating and Activating Monitoring Groups
To create and activate SNMP Interface Monitoring Groups go to the Nectus Home Screen and select Monitoring -> SNMP Monitoring Groups -> Interface Monitoring Groups.
This opens the “Interface Monitoring Groups” dialog box.
Nectus provides you with two predefined Monitoring Groups:
Click the Add Group button to open the “Add Monitoring Interface Group” dialog box and create an additional Monitoring Group.
To monitor a group, check its Enable Monitoring box in the “Interface Monitoring Groups” dialog box.
Next select the Monitoring Profile you want to use for the Group. See the next section for more information on Monitoring Profiles.
Then click the Edit Alert Recipients icon to open the “Alert Recipients” dialog box and select lists that specify who will receive alerts from this particular Monitoring Group and Profile.
3. Creating and Customizing Monitoring Profiles
Each Monitoring Group must have a Monitoring Profile that determines which parameters are monitored. You can customize each Profile, and create individual Profiles for each Monitoring Group.
To create a new Profile, go to the Nectus Home Screen and select Monitoring -> SNMP Monitoring Profiles -> Profiles – SNMP Interface Monitoring. This opens the “Interface Monitoring Profiles” dialog box. Click the Add Profile button to create a new Profile.
To edit a Profile click the Edit icon to the right of the Monitoring Profile for the Group. This opens the “Edit Device Monitoring Profile” dialog box.
Some of the parameters here allow you to set Threshold values or other customizations.
Set the Enabled checkbox next to each Parameter you want to monitor. Check any of the Log to DB, Email Alerts, SMS Alerts, or Traps Alerts boxes to send those types of alerts.
4. Customizing Alerts
To customize the alerts, click the Edit Alert Templates button to open the “Edit Alert Handler” dialog box.
If you select Email Alerts or SMS Alerts, Nectus will generate Alert messages when the Monitored Parameter exceeds threshold and Recovery messages when the Parameter returns to normal.
Selecting the tab for one of these messages allows you to customize the appearance of that message.
5. Placing Interfaces in Monitoring Groups
Once you have created the Monitoring Groups you want to use you need to place Interfaces in them. To do so, click the Monitoring Group Name to open the “Edit Monitoring Interface Group” dialog box.
Select the Group you want to add Interfaces to on the left, and the Group you want to take them from on the right. Use the arrows to move Interfaces between the two Interface Groups.
Note that if you move an Interface that is currently being monitoring into the No Monitoring Group, Nectus will immediately stop monitoring that Interface. This can be useful for situations where you know an Interface will be down for some time (extended maintenance, for example) and you don’t want the system to send alerts.
Network Device SVG Icon Library
Nectus News, Technical NotesEnabling Monitoring for SNMP devices
Network MonitoringEnabling Monitoring for SNMP Devices
In this chapter, you’ll learn how to enable monitoring and create monitoring groups for SNMP Devices.
The specific topics we will cover in this chapter are:
1. Automatic Discovery and Grouping of SNMP Devices
Nectus automatically discovers all live SNMP Devices. These devices are listed in the SNMP Devices Panel on the Home Screen. While Devices are detected automatically, they are not automatically monitored. New SNMP Devices are automatically added to the default “No Monitoring” Group.
To Enable monitoring for a Device you need to move it from “No Monitoring” group to any
of the group where monitoring is enabled.
2. Creating and Activating Monitoring Groups
To create and activate SNMP Device Monitoring Groups go to the Nectus Home Screen and select Monitoring -> SNMP Monitoring Groups -> Device Monitoring Groups.
This opens the “Device Monitoring Groups” dialog.
Nectus provides you with two predefined Monitoring Groups:
Click the Add Group button to open the Add Monitoring Device Group dialog and create an additional Monitoring Group.
To monitor a group, check its Enable Monitoring box in the Device Monitoring Groups dialog box.
Next select the Monitoring Profile you want to use for the Group. See the next section for more information on Monitoring Profiles.
Next click the Edit Alert Recipients icon to open the Alert Recipients dialog box and select lists that specify who will receive alerts from this particular Monitoring Group and Profile.
3. Creating and Customizing Monitoring Profiles
Each Monitoring Group must have a Device Monitoring Profile that determines which parameters are monitored. You can customize this Profile, and create additional Profiles for each Monitoring Group.
To edit the default Profile or create a new one, click the Edit icon to the left of the Monitoring Profile for the Group. This opens the Edit Device Monitoring Profile dialog box.
Each of the four tabs in this dialog contains parameters you can monitor. Many of the parameters allow you to set Threshold values or other customizations.
Set the Enabled checkbox next to each Parameter you want to monitor. Check any of the Log to DB, Email Alerts, SMS Alerts, or Traps Alerts boxes to send those types of alerts.
4. Customizing Alerts
To customize the alerts, click the Edit Alert Templates button to open the Edit Alert Handler dialog box.
If you select Email Alerts or SMS Alerts, Nectus will generate Alert messages when the Parameter goes out of bounds and Recovery messages when the Parameter returns to normal.
Selecting the tab for one of these messages allows you to customize the appearance of that message.
5. Placing Devices in Monitoring Groups
Once you have created the Monitoring Groups you want to use you need to place Devices in them. To do so, click the Monitoring Group Name to open the Edit Monitoring Device Group dialog box.
Select the Group you want to add Devices to on the left, and the Group you want to take them from on the right. Use the arrows to move Devices between the two Device Groups.
Note that if you move a Device that is currently being monitoring into the No Monitoring Group, Nectus will immediately stop monitoring that Device. This can be useful for situations where you know a device will be down for some time (extended maintenance, for example) and you don’t want the system to send alerts.
Nectus Partner Program
Nectus NewsWe are very happy to announce the launch of our Nectus Partner Program.
We are inviting all Professional Services Organizations and Independent consultants to become an Integration Partner for the best Network Monitoring Solution of 2018 and take advantage of enormous commissions that we offer to all of our Nectus Partners.
Please contact sales@nectus5.com for additional details.
Nectus Feature List
Nectus News, Technical NotesNectus Feature List (October 2018)
Many more coming in 2019 .. !!!
Nectus Distributed Architecture
Nectus Installation, Nectus News, Technical NotesNetwork Redundancy Visualization (Pure Art)
Nectus News, Network Topology Visualization, Technical NotesAnother piece of art generated by Nectus with a help of D3.JS library. Discovery of small Datacenter was completed under 3 minutes and topology generated under 5 seconds.
Conversion to Visio is supported in Nectus starting from 1.2.40.
Real-time Device and Link status is overlayed in this topology making it suitable for NOC level monitoring.
Keeping Track of Your Telco Circuits
CircuitDB, Nectus News, Technical NotesKeeping Track of Telco Circuits
Remember that awkward moment when you discovered that you still paying for the circuit that suppose to be decommed 2 years ago?
I do.
Keeping track of the Telco circuit is important on many levels: financial and technical.
Having Circuit ID ready and knowing where to call when circuit goes down can make a difference between 6-hour outage and 30 minutes.
Keeping track of all the contracts for each circuit is also important for managing your budget. Beyond that, the end of a contract offers you the opportunity to negotiate better contract terms for that circuit in the future.
A typical IT organization can lease dozens, sometimes hundreds or even thousands of circuits from external providers. Whether Internet circuits, Dark-Fiber, MPLS circuits, Telephone circuits, each circuit has a lot of information associated with it.
Nectus includes a built-in database, called CircuitDB, to help you keep track of all the information related to all your circuits. This database can give you both a high-level view and a detailed view for every circuit.
Getting a High-Level View of Your Circuits
The high-level view of your circuits shows the basic information about each end of a circuit. When you open CircuitDB you get a table showing this high-level view for every circuit you have added to CircuitDB.
Opening CircuitDB
To open CircuitDB go to the Nectus Home Screen open Tools and click CircuitDB.
One thing to notice here is that Nectus shows the Up or Down status of a circuit in real time. This is indicated by the red or green icon to the left of Interface A.
If you have a lot of circuits in the database, you can search for a specific circuit by name or ID, or filter the table by Site, Carrier, Circuit Type, or Circuit Status.
High-Level Fields in CircuitDB
The high-level fields in CircuitDB are:
Getting a Detailed View of Your Circuits
To get all the details about a particular circuit, click the Edit CircuitDB icon to the right of the Circuit ID. This opens the Update CircuitDB dialog.
Full Set of Fields for a Single Circuit
Here is the full set of fields for a single circuit. It is divided into two sections.
The first section deals with the physical connections of the Circuit and is duplicated for End Point A and End Point B:
The second section deals with the contract for the Circuit:
Dark or Light? Heated Debate over Dashboard Color Theme
Nectus News, Technical NotesGenerating Site Network Topology in Nectus
Nectus News, Network Topology Visualization, Technical NotesVisualizing Network Topology
In this chapter, you’ll learn how to generate a map of the L2 Topology for your site. An L2 Topology shows the physical connections between devices, which can be extremely useful for maintenance and troubleshooting. The topology can display real-time up/down status information along with other relevant information about the site.
The specific topics we will cover in this chapter are:
Generating an L2 Topology
You can generate an L2 Topology for any site in just a few steps. The devices that appear in this topology are those that were found during the nightly site discovery operation.
1.1 Generate the L2 Topology
Follow these steps to generate the L2 Topology for a site:
Manipulating the L2 Topology
The L2 Topology displays the physical connections between the devices at the site, along with information about those connections. You can drag the entire Topology around the window, as well as drag and resize individual devices.
Open the Topology toolbar in the top left of the window for the additional options shown here:
Changing L2 Topology Settings
Click Settings in the L2 Topology window to open the Settings dialog and customize the information that appears in the Topology.
Assign the Topology a Title if you plan to reuse it.
In the Device Info tab, check Up-Down Status and the type of alert (Color Alert, Audio Alert) for real-time alerts when a device in the Topology is down. With Color Alerts, both the device that is down, and the title of the Topology will flash red as shown in the Topology image above.
Be sure to click the Save icon in the Topology Toolbar to save your changes.
Automated network topology visualization with Nectus
Nectus News, Network Topology Visualization, Technical NotesNectus PowerPoint Feature Presentation
Nectus News, Technical NotesNectus Overview
Cascading Syslog Servers
Syslog, Technical NotesCascading Syslog Servers
Introduction to the Syslog Protocol
Syslog is a protocol that allows systems to send Event Notification Messages through IP networks to Syslog Servers (also known as Event Message Collectors). There the messages can be sorted, searched, and analyzed to monitor the state of individual devices as well as the overall system.
Syslog messages contain both status information and a Severity Level, which ranges from 0 (zero) to 7. Level 0 messages are emergencies. Level 7 messages signify that the sender is in Debug mode. The meanings of Levels 1 through 6 are application dependent.
2. Multiple Syslog Servers – The Traditional Approach
In some situations you might want to add additional Syslog Servers to your system. Traditionally you would do this by configuring each connected device or server to send messages to the Main Syslog Server and to each Secondary Syslog Server. This configuration is shown in the following image:
This works fine if you just have a few devices. But it quickly becomes impractical as the number of connected devices grows. Imagine configuring 1000+ devices to send Syslog messages to one or more additional servers for a special project, then disconnecting them all later.
This makes the traditional approach impractical for large installations.
3. Multiple Syslog Servers – The Cascading Approach
To avoid the problems of the traditional approach, Nectus implements Cascading Syslog Servers. Instead of connecting each device to each Syslog server, you need only connect them to the primary Syslog server. The primary server can then forward copies of the messages to any secondary servers, as shown in the following image:
This approach makes adding and removing secondary Syslog servers simple. However, forwarding every Syslog message does increase the load on the primary Syslog server. You need to carefully monitor the primary server to avoid overloading it.
Nectus recommends you cascade no more than 10 secondary Syslog servers to avoid overloading the primary server.
3.1 Configuring the Nectus Cascading Syslog Servers Solution
Follow these steps to configure Cascading Syslog Servers:
AWS Backup Automation with Nectus
AWS Monitoring, Nectus News, Technical NotesAWS Instance Backup Automation with Nectus
Having your data backed up and secured is crucial for business-critical systems. If your servers run in AWS infrastructure,
then you already have an advantage of performing backup of the hosted instances using Amazon built-in features.
This can be performed manually using AWS console the following way. First, select Instances menu from EC2 Dashboard.
Then select an instance you would like to backup.
In Description tab you will see the Block devices attached to the selected instance.
Clicking on one of the block devices will bring up the window displaying the block device’s EBS ID:
By clicking that EBS ID you get to the Volumes menu of the EC2 Dashboard:
Right-click on the selected volume will display a menu with “Create snapshot” option.
After selecting this option you have to enter a description of your snapshot and the snapshot will be created.
After that the snapshot created will appear on the list displayed on the EC2 Dashboard/Snapshots page. To restore data from that snapshot you should select
“Create Volume” option from the snapshot’s context-menu. A new volume will appear with exactly the same data you had on your volume when snapshot was created.
But taking snapshots manually is hardly an option, especially if you deal with a lot of the EC2 instances. This process must be automated.
One of possible solutions is utilizing the Nectus AWS backup functionality. Nectus is able to take snapshots of your volumes constantly and
regularly with the required periodicity according to the backup profiles you set.
The following steps will show how to enable and set up the automated backup of AWS instances using Nectus. First you need to set up your backup profiles.
Select Settings/General Settings/AWS Integration menu.
In the “Backup” tab you will see backup profiles already created and also the “Add Backup Profile” button.
Pressing this button will open the following “Add New AWS Backup Profile” dialog.
Here you can enter a name for a new backup profile, periodicity of snapshots creation (Snapshot Interval), period of retention for snapshots created (Snapshot retention)
and the allowed time interval to take snapshots (this setting is available only if Snapshot Interval is 1440 minutes or more).
Pressing “Save” button will add the new backup profile to the list. Editing of existing profiles is also possible.
You can create any number of backup profiles for different purposes.
For example, you may want to backup your most critical production instances quite often (every 5 minutes) but your test servers rarely (once a day or maybe even once a week).
The procedure of taking a snapshot is free of charge from Amazon but storing them is charged depending on the volume (see AWS EC2 pricing).
That should be considered when choosing the Snapshot retention period.
After you have set the required backup profiles, it is time to assign them to your instances. To perform it select “AWS Instances” from the “Inventory” menu.
In the form displayed you can see a list of already existing instance groups. To create a new AWS instance group press the button “Create new Group” at the top-right of the form.
In the window opened you should set a new group name, check the “Enable Backup” box and choose one of the backup profiles created earlier.
If the box is not checked, then no backups will be performed for instances of this group.
Now when you have backup profiles assigned to AWS instance groups you can switch to the next tab “AWS Instances”.
The next window displays a list of AWS instances.
Each instance belongs to one of the AWS instance groups and so the group settings affect the instance backup policy.
To change backup profile for an instance you should move it to another instance group with appropriate backup profile.
For example, if you want to change backup profile for “www.nectus5.com” from “Weekly Backups” to “Daily Backups”
just click on the Instance ID and change AWS instance group.
After such setup Nectus will automatically start creating new snapshots and deleting old ones.
You will see those snapshots in your EC2 Dashboard.
Creating custom Dashboards in Nectus
Nectus Dashboards, Nectus News, Technical NotesCreating Custom Dashboards
In this chapter, you’ll learn how to create Custom Dashboards. Nectus lets you create an unlimited number of Custom Dashboards, making it easy to focus on exactly the information you need at any time.
This chapter covers how to:
1. Create a New Custom Dashboard
You create and configure Custom Dashboards using the Dashboard Widgets dialog box.
2. Add Widgets
The Dashboard Widgets dialog includes all the available Widgets grouped by Category. You can enable any number of Widgets from any number of Categories in the Dashboard.
Many Widgets have settings you can enter when you add them to the Dashboard. They may also have additional settings you configure once the Widget is live in the Dashboard. See the next section for more details.
3. Manage Widgets
Once a Widget is live in a Dashboard, you can drag it, resize it, or remove it.
You can customize any Widget by clicking its Settings icon. Most Widgets have a Style setting you can configure. Some Widgets also have Views. Views filter the information that appears in the Widget.
In the following example, the View filters the High Utilization Interfaces Widget so only interfaces that have had utilization levels of 70% of above in the last hour appear.
To keep any changes you make to widgets, click the Dashboard’s Save icon.
4. Manage Dashboards
You manage a Dashboard by clicking the Dashboard’s Settings icon to open the Dashboard Widgets dialog box. You can change the Title, as well as add or remove Widgets.
To keep any changes you make to the Dashboard, click the Save icon.
To make this Dashboard the default, click the Open by Default icon.
5. Available Widgets by Category
Nectus gives you over 60 Widgets, divided into over a dozen Categories. This section lists the Categories and the Widgets in each Category.
5.1 Device Widgets
5.2 Interface Widgets
5.3 SQL DB Widgets
Locks (Total)
5.4 Syslog Widgets
5.5 Wireless Widgets
5.6 HTTP Widgets
5.7 Server Health Widgets
5.8 Custom Graphs Widgets
5.9 Outage Map Widgets
5.10 Netflow Widgets
5.11 Call Manager
5.12 AWS
5.13 Others
WHICH US CITY USES THE MOST IPV4 PUBLIC ADDRESSES?
Nectus News, Technical NotesNote: Information is based on Nectus IP geo-location service
Creating Network Outage Dashboards in Nectus with GoogleMaps
Nectus Dashboards, Nectus News, Technical NotesCreate an Outage Map
In this chapter, you’ll learn how to create and use Outage Maps. An Outage Map is a graphical representation of the status of the Sites in your organization. Using real world maps and GPS coordinates, an Outage Map instantly shows you outages for any of your Sites in any region of the world.
This chapter covers how to:
Obtain and Configure a Google Map API Key
Nectus needs an API key to work with Google Maps. Obtaining a Google Map API Key is outside the scope of this guide. Google provides detailed instructions for obtaining a key at:
https://developers.google.com/maps/documentation/javascript/get-api-key
Once you acquire a key, follow these steps to configure Nectus to work with your key:
2. Create an Empty Outage Map
To create an empty Outage Map, go to the Nectus Top Menu then navigate to: Monitoring -> Outage Map Dashboards -> Outage Map Dashboard.
Note: Nectus supports up to 10 maps and can display any or all of them simultaneously. See Section 2.3 for instructions on creating and displaying additional maps.
2.1 Zoom In to the Geographical Area of Interest
2.2 Assign and Save a Map Name
2.3 Display Multiple Maps Simultaneously
It can sometimes be helpful to display multiple Outage Maps simultaneously. Nectus can display up to 10 maps at once. Each map has its own adjustable settings and can be zoomed and configured independently.
3. Place Sites on the Outage Map
To place a Site on the Outage Map, you need to enter the GPS coordinates in the Site Properties. You can either enter the coordinates manually, or you can let Nectus derive the coordinates of the Site from its Address.
3.1 Enter the GPS Coordinates Manually
Enter the GPS coordinates in the GPS Latitude and GPS Longitude fields.
3.2 Derive GPS Coordinates from the Address
If you don’t know the GPS coordinates of the Site, enter the Site Address and click Find GPS from Address. Nectus derives the GPS coordinates from the Address and enters them for you.
3.3 Understand Site Colors
The color of a Site’s icon on the map gives you an easy way to check the status of the Devices at that Site. Each Site icon can have one of three colors:
3.4 Access a Site Context Menu from a Map
If a Site appears on a map, you can open its context menu directly, without having to navigate through the Sites Panel. Simply right-click the icon of the Site.
3.5 Removing a Site from a Map
To remove a Site from any and all maps without removing the Site from the Nectus database, clear its GPS coordinates in its Site Properties.
4. Configure Outage Map Parameters
An Outage Map has several configurable parameters that control how things appear on the map. You can configure each map independently of the others, giving you maximum flexibility to get exactly the information you need. The following sections show you how to configure these parameters.
4.1 Change the Shape and Size of Individual Site Icons
Changing the shape or size of certain Site icons makes it easy to pick out those Sites on a crowded map. You might make your most important Sites larger than the rest, or assign them a different shape.
To change the shape and size of individual Site icons, navigate to Site Properties. In the Outage Map Icon Size field select the icon size in pixels. Use the Outage Map Icon list to select a Circle, Star, or Triangle for the shape.
4.2 Change the Size of All the Site Icons on a Map
To scale all the icons on a map simultaneously navigate to: Map Settings -> General tab. In the Set Circle Radius (%) field enter a scaling factor that will apply to all the Site icons on this particular map. The following figure shows the map from section 4.1 with the icons scaled down to 50% of their original size.
4.3 Show or Hide Site Names
Every Site must have a Site Level Name, but you control whether Nectus displays those names on a map.
To show or hide all the Site Level Names on a map simultaneously navigate to: Map Settings -> General tab and check or uncheck Site Name.
4.4 Display of Hide Map Objects
Outage Maps can display a huge amount of information, not all of which may be useful to you. You can configure a map to display only those objects that are relevant to you.
To show or hide all the Site Level Names on a map simultaneously navigate to: Map Settings -> Google Map tab. Check or uncheck Map Objects as desired.
Network and Server Uptime Calculation Considerations for Monitoring tools
Nectus News, Technical NotesNetwork and Server Uptime Calculation Considerations for Monitoring tools
Uptime is one of the most important IT infrastructure operational metrics that gives an overview how “stable” or “reliable” your IT infrastructure is with 99.9999% uptime being a platinum standard.
But how do you calculate an Uptime?
In ideal (continuous and none-discrete) world calculation of Uptime is somewhat simple.
Take number of seconds in monitoring period and number of seconds when monitored object was down and use simple formula:
Uptime = 100 – ((Outage duration / Total time) * 100)
Example:
Monitoring Period: 1 year = 31,536,000 seconds
Total Object Outage Duration: 300 seconds
Object Uptime: 99.999%
Monitored Objects achieving “six nines” uptime should only be “down” for a maximum 31.5 seconds in the 365 days.
But as you get to “six nines” or higher, capabilities and configuration of monitoring tools starts to play critical role in accuracy of uptime calculations.
Single Server Example
Let’s start with an example of Uptime calculation for a single device such as a Server.
First, we need to define what constitutes a server being up or down and what tools we planning to use to determine its state.
Let assume that we use a classic ICMP v4 probing with ‘Polling Interval” equal to 1 second.
In other words, we will be sending Ping packets from a monitoring agent to the Server every 1 second and if server does not respond we shell consider it down.
Simple enough?
Well, may be in perfect world yes, but we live in real world and packets may get lost for reason other than Server being down.
Packets may get lost due to traffic shaping, CRC errors and many other reasons. So, to prevent influx of false positive Server down events we need to increase number
of consecutive packets that must be missed to consider Server to be “down” to a number greater than 1.
Let’s call this number an “Assurance Multiplier”.
Greater “Assurance Multiplier” values shell result in greater probability that we detect an actual Server down event. But at the same time greater “Assurance Multiplier” will result in slower detection time for Server down events and inability to detect short-lived outages with duration time less than (Assurance Multiplier * Polling interval) seconds.
We also need to introduce two new parameters: “Actual Outage Duration” and “Detected Outage Duration” to reflect the fact that duration of the Server outage calculated by monitoring agent may be slightly greater than actual outage of the Server due to the fact that duration of polling interval is > 0.
Summary
“Polling Interval” – Time between two consecutive state polls.
“Assurance multiplier” – Number of consecutive polling intervals when object’s state must be Down to consider monitored object to be truly down.
“Outage Detection Time” – Time is takes for monitoring Agent to detect an outage of the monitored object after outage has started.
“Actual Outage Duration” – Actual Outage Duration of the monitored object.
“Calculated Outage Duration” – Duration of the Outage as calculated by the monitored object.
Considering that Actual Outage Duration > (Polling Interval * Assurance Multiple) worst case scenarios should be calculated as following:
Outage Detection Time = (Polling Interval * Assurance Multiplier) + Polling Interval
Calculated Outage Duration = (Polling Interval * Assurance Multiplier) + 2 * Polling Interval
Lets do the math with following Monitoring Agent Configuration Example : Polling Interval = 1 Sec and Assurance Multiplier = 3
We get following results:
Outage Detection Time = 4 Seconds
Best Detectable Actual Outage > 3 Seconds
Best Calculated Outage Duration > 5 Seconds
Now we can see that provided example of Monitoring Agent configuration is sufficient for grading Server’s Uptime as 99.9999% but not sufficient for 99.99999% classification.
To classify monitoring tool for 99.99999% accuracy you need to decrease Polling Interval or decrease Assurance Multiplier by at least 30%.
So next time when you see a 99.99999% Uptime calculated by a Monitoring tool with a Polling interval of 5 minutes you know that it is likely not true.
It gets more interesting when we move into calculation of Uptime for a Network rather than a single object like Server.
Creating Hierarchical Site Structure in Nectus
Nectus News, Site Creation and Management, Technical NotesCreating Hierarchical Site Structure in Nectus
In this chapter you’ll learn how to create a Hierarchical Site Structure in Nectus and populate it with Devices. This activity is fundamental to using Nectus.
Specifically, you will learn how to:
Creating a New Site
Like everything in Nectus, creating a Site is fast and simple. Follow these instructions to get it done:
Deleting a Site
Deleting an existing Site is even easier than creating a new one. Follow these steps:
Moving a Site
You can move a Site to a new location in the existing hierarchy. This location can be at the same level in the hierarchy or at any other level. Any Site can be moved to any location within the hierarchy. Follow these instructions to move a Site:
Adding a Device to a Site
Here, we are assuming that you have already added your available Devices to the Unassigned Devices list. Follow these steps to add a Device to a Site by taking it from the Unassigned Devices pool:
Deleting a Device from a Site
Follow these steps to delete a Device from a Site by moving it back to the Unassigned Devices pool:
Moving a Device to a Different Site
Moving a Device between Sites is very similar to deleting a device. Here are the steps:
Editing Site Properties in Nectus
Nectus News, Site Creation and Management, Technical NotesEdit Site Properties
You can easily edit the properties of any existing Site. In this chapter, you’ll learn how to edit the properties of an existing Site. We’ll also discuss the functions of each editable property.
Opening the Edit Site Properties Dialog Box
It takes just a few clicks to open the Edit Site Properties dialog box for any existing Site. Follow these instructions:
Editable Properties
You can edit the following properties from the Edit Site Properties dialog box. Here is a complete explanation of each field: